チュートリアル:SIMDRegisterクラスを使用した最適化
プロセッサの並列性を活用して、単一命令複数データ計算を実行します。並行処理を導入せずにオーディオアプリケーションを最適化します。
レベル: 上級
プラットフォーム: Windows, macOS, Linux
クラス: dsp::SIMDRegister, dsp::IIR, dsp::ProcessorDuplicator, AudioDataConverters, dsp::AudioBlock, HeapBlock
はじめに
このチュートリアルのデモプロジェクトをこちらからダウンロードしてください:PIP | ZIP。プロジェクトを解凍し、最初のヘッダファイルをProjucerで開いてください。
この手順でサポートが必要な場合は、チュートリアル:Projucer Part 1: Projucerを始めようを参照してください。
デモプロジェクト
デモプロジェクトは、ロードされたオーディオファイルをIIRフィルターを通じて再生し、試聴時に処理および変更することができます。この最適化の目的は、同じIIRフィルターでSIMD命令セットを使用してどれだけCPUパワーを軽減できるかを確認することです。
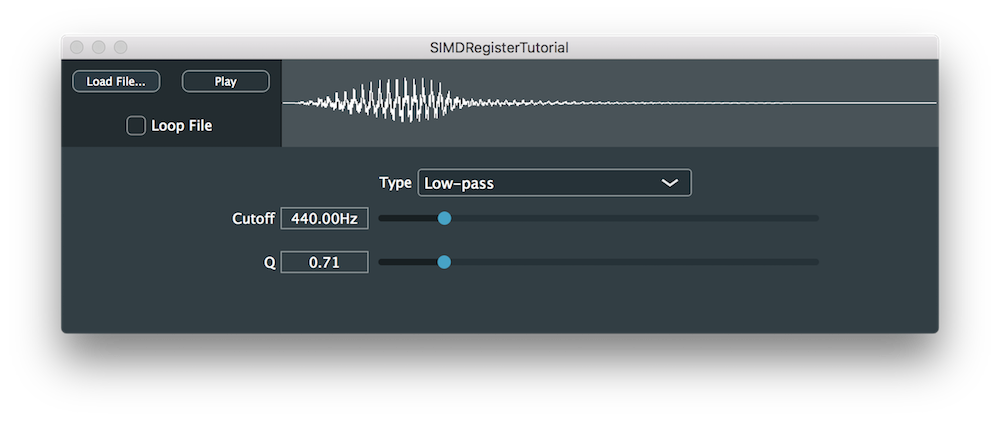
ここで紹介するコードは、DSP DemoのSIMDRegisterDemoとほぼ同様です。
SIMD命令
SIMDは「Single Instruction Multiple Data(単一命令複数データ)」の略で、最新のCPUが数値を複数のレジスタにロードし、同じ計算を一度に実行することで、データセットに単一の命令を適用できる方法を指します。デジタル信号処理の世界では、このタイプの並列性は、MIMD(Multiple Instruction Multiple Data)などの他のタイプよりも好まれます。なぜなら、オーディオレベルでは並行性が問題になるからです。オーディオスレッドが他のスレッドとデータを奪い合わないようにすることが最重要であり、オーディオを処理するときは命令の順序をほとんどの場合同じ順序に保つ必要があります。
SIMDは個々のデータではなくデータストリームのベクトルに対して動作するため、オーディオバッファからデータブロックを受信することに慣れているオーディオ処理にさらに適しています。SIMDは、複数のデータポイントに同じスカラー演算を適用する必要があるときにも優れており、これはDSPアルゴリズムで非常に一般的なことです。
一般的なコードを最適化するプロセスは、現在では通常コンパイラによって自動的に行われますが、DSPアルゴリズムのベクトル化は常に簡単ではありません。コンパイラは常に人間的にアルゴリズムが何をしようとしているかを理解して正しく最適化できるわけではありません。したがって、このタスクは通常手動で行われ、SIMDRegisterクラスはJUCEでこれを行うための便利なツールです。
SIMDRegisterクラスは、異なるプロセッサタイプを処理するため便利です。CPUによって、レジスタのサイズと数は異なり、すべてのCPUベンダーを考慮することは急速に困難になります。これはすべてSIMDRegisterクラスによって処理され、アルゴリズムでベクトル化したい命令セットを指定するだけで済みます。
SIMDRegisterクラスの使用は比較的簡単で、本質的にプリミティブ型のドロップイン置換として機能します。このような簡単な例コードを見てみましょう:
float calculateDSPEffect (float x,
float y)
{
auto z = x + (y * 2.0f);
return z;
}
これは、プリミティブ型をSIMDRegisterクラスで単純にラップすることで簡単にベクトル化できます:
SIMDRegister<float> calculateDSPEffect (SIMDRegister<float> x,
SIMDRegister<float> y)
{
auto z = x + (y * 2.0f);
return z;
}
DSPコードでは、条件文は非常に遅く、分岐は一般的にできるだけ避けるべきです。したがって、以下の例はSIMD最適化の良い候補です:
float calculateDSPEffect (float x,
float y)
{
auto z = (x > y ? x + (y * 2.0f) : y);
return z;
}
幸いなことに、SIMDRegisterクラスは、以下のように正しい結果を選択できるビットマスクを提供します:
SIMDRegister<float> calculateDSPEffect (SIMDRegister<float> x,
SIMDRegister<float> y)
{
auto mask = SIMDRegister<float>::greaterThan (x, y);
auto z = ((x + (y * 2.0f)) & mask) + (y & (~mask));
return z;
}
このチュートリアルの目的では、SIMDを使用してIIRフィルターを最適化するので、まずIIRフィルターの実装を見てみましょう。
IIRフィルター
SIMDTutorialFilterクラスで、まずフィルターのパラメータなどのメンバー変数を以下のように定義します:
dsp::ProcessorDuplicator<dsp::IIR::Filter<float>, dsp::IIR::Coefficients<float>> iir;
ChoiceParameter typeParam { { "Low-pass", "High-pass", "Band-pass" }, 1, "Type" };
SliderParameter cutoffParam { { 20.0, 20000.0 }, 0.5, 440.0f, "Cutoff", "Hz" };
SliderParameter qParam { { 0.3, 20.0 }, 0.5, 0.7, "Q" };
std::vector<DSPParameterBase*> parameters { &typeParam, &cutoffParam, &qParam };
double sampleRate = 0.0;
};
ProcessorDuplicator内でIIRフィルターオブジェクトを定義することで、各チャンネルで個別にprepare()、process()、reset()関数を呼び出すことを心配せずに、モノプロセッサをマルチチャンネルに自動的に変換できます。また、パスフィルターのタイプ、カットオフ周波数、フィルターのシャープネスQなどのフィルターのパラメータを定義します。
updateParameters()関数で、画面上のコントロールが変更されたときにフィルターのパラメータが更新されることを確認します:
void updateParameters()
{
if (sampleRate != 0.0)
{
auto cutoff = static_cast<float> (cutoffParam.getCurrentValue());
auto qVal = static_cast<float> (qParam.getCurrentValue());
switch (typeParam.getCurrentSelectedID())
{
case 1:
*iir.state = *dsp::IIR::Coefficients<float>::makeLowPass (sampleRate, cutoff, qVal);
break;
case 2:
*iir.state = *dsp::IIR::Coefficients<float>::makeHighPass (sampleRate, cutoff, qVal);
break;
case 3:
*iir.state = *dsp::IIR::Coefficients<float>::makeBandPass (sampleRate, cutoff, qVal);
break;
default:
break;
}
}
}
パラメータが変更されるたびに、サンプルレート、カットオフ周波数、Qに応じた新しい係数セットでIIRフィルターの新しい状態を作成します。DSPモジュールは、makeLowPass()、makeHighPass()、makeBandPass()関数をそれぞれ使用して、3つのフィルタータイプに便利な係数を提供します。
prepare()関数で、ProcessSpecオブジェクトからサンプルレートを設定し、ローパスフィルターのデフォルトケースでIIRフィルター係数を設定し、処理コンテキストに関する情報を持つprepare()関数を使用してフィルターを準備します:
void prepare (const dsp::ProcessSpec& spec)
{
sampleRate = spec.sampleRate;
iir.state = dsp::IIR::Coefficients<float>::makeLowPass (sampleRate, 440.0);
iir.prepare (spec);
}
フィルターでオーディオファイルを処理するのは簡単で、process()関数で、入力と出力の両方に単一のブロックが使用されるコンテキストでフィルターのprocess()関数を呼び出します:
void process (const dsp::ProcessContextReplacing<float>& context)
{
iir.process (context);
}
最後に、reset()関数でフィルターのresetを呼び出してフィルターをリセットします:
void reset()
{
iir.reset();
}
では、このIIRフィルターを最適化しましょう。
SIMD最適化されたIIRフィルター
IIRフィルターのコードを最適化する前に、システムでSIMDが利用可能であることを確認する必要があります。JUCE_USE_SIMDマクロを使用して、以下のようにフィルター実装全体をラップすることで、SIMDマシンで開発しているかどうかを確認します:
#if JUCE_USE_SIMD
//==============================================================================
template <typename T>
static T* toBasePointer (dsp::SIMDRegister<T>* r) noexcept
{
return reinterpret_cast<T*> (r);
}
constexpr auto registerSize = dsp::SIMDRegister<float>::size();
struct SIMDTutorialFilter
{
};
#endif
まず、SIMDTutorialFilterクラスの下部に、IIRフィルターのメンバー変数、および処理を容易にするためのAudioBlockとHeapBlockオブジェクトを定義しましょう:
dsp::IIR::Coefficients<float>::Ptr iirCoefficients; // [1]
std::unique_ptr<dsp::IIR::Filter<dsp::SIMDRegister<float>>> iir;
dsp::AudioBlock<dsp::SIMDRegister<float>> interleaved; // [2]
dsp::AudioBlock<float> zero;
juce::HeapBlock<char> interleavedBlockData, zeroData; // [3]
ChoiceParameter typeParam { { "Low-pass", "High-pass", "Band-pass" }, 1, "Type" };
SliderParameter cutoffParam { { 20.0, 20000.0 }, 0.5, 440.0f, "Cutoff", "Hz" };
SliderParameter qParam { { 0.3, 20.0 }, 0.5, 0.7, "Q" };
std::vector<DSPParameterBase*> parameters { &typeParam, &cutoffParam, &qParam };
double sampleRate = 0.0;
IIR係数をポインタとして定義し、フィルターをサンプルタイプをラップするSIMDRegisterクラスを使用してユニークポインタとして定義します[1]。サンプルタイプをラップするSIMDRegisterクラスを使用してインターリーブデータを格納するAudioBlockと、後で出力ブロックを格納するために使用されるゼロデータ用の別のAudioBlockを作成します[2]。対応するAudioBlockオブジェクトといくつかのチャンネルポインタをSIMDRegisterベクトルの要素数のサイズで保持するためのHeapBlockオブジェクトを割り当てます[3]。
prepare()関数で、以前と同様にサンプルレートを設定し、フィルターのデフォルト係数を計算します[4]。サンプルタイプの周りにSIMDRegisterラッパーと先に定義した係数を持つ新しいIIRフィルターをインスタンス化することでフィルターをリセットします[5]:
void prepare (const dsp::ProcessSpec& spec)
{
sampleRate = spec.sampleRate; // [4]
iirCoefficients = dsp::IIR::Coefficients<float>::makeLowPass (sampleRate, 440.0f);
iir.reset (new dsp::IIR::Filter<dsp::SIMDRegister<float>> (iirCoefficients)); // [5]
interleaved = dsp::AudioBlock<dsp::SIMDRegister<float>> (interleavedBlockData, 1, spec.maximumBlockSize);
zero = dsp::AudioBlock<float> (zeroData, dsp::SIMDRegister<float>::size(), spec.maximumBlockSize); // [6]
zero.clear();
auto monoSpec = spec;
monoSpec.numChannels = 1;
iir->prepare (monoSpec); // [7]
}
先に定義した対応するHeapBlockオブジェクトを割り当てることで、インターリーブデータとゼロデータのAudioBlockオブジェクトを作成します[6]。インターリーブデータブロックは1チャンネルのみを必要とし、最大ブロックサイズはコンテキスト情報から取得されます。ゼロデータブロックはSIMDRegisterベクトルのサイズを取り、処理前にクリアされます。フィルターは、マルチチャンネルサンプルが後でインターリーブされ、1チャンネルとして処理されるため、現在のコンテキスト情報でチャンネル数をモノに減らして準備されます[7]。
最後に、process()関数で、以下のように最適化された処理のためにサンプルをインターリーブします:
void process (const dsp::ProcessContextReplacing<float>& context)
{
jassert (context.getInputBlock().getNumSamples() == context.getOutputBlock().getNumSamples());
jassert (context.getInputBlock().getNumChannels() == context.getOutputBlock().getNumChannels());
const auto& input = context.getInputBlock(); // [9]
const auto numSamples = (int) input.getNumSamples();
auto inChannels = prepareChannelPointers (input); // [10]
using Format = juce::AudioData::Format<juce::AudioData::Float32, juce::AudioData::NativeEndian>;
juce::AudioData::interleaveSamples (juce::AudioData::NonInterleavedSource<Format> {
inChannels.data(),
registerSize,
},
juce::AudioData::InterleavedDest<Format> { toBasePointer (interleaved.getChannelPointer (0)), registerSize },
numSamples); // [11]
iir->process (dsp::ProcessContextReplacing<dsp::SIMDRegister<float>> (interleaved)); // [12]
auto outChannels = prepareChannelPointers (context.getOutputBlock()); // [13]
juce::AudioData::deinterleaveSamples (juce::AudioData::InterleavedSource<Format> { toBasePointer (interleaved.getChannelPointer (0)), registerSize },
juce::AudioData::NonInterleavedDest<Format> { outChannels.data(), registerSize },
numSamples); // [14]
}
- [8]:まず、入力ブロックと出力ブロックでサンプル数とチャンネル数が同じであることを確認します。
- [9]:次に、入力ブロックと処理するサンプル数を取得します。
- [10]:SIMDRegisterの各チャンネルについて、チャンネルが入力チャンネルかどうかを確認し、チャンネルポインタを対応するHeapBlockにコピーします。そうでない場合、それは出力チャンネルであり、ゼロデータチャンネルポインタをコピーします。
- [11]:次に、チャンネルポインタHeapBlockからインターリーブAudioBlockにコピーし、サンプル数とSIMDRegisterサイズとしてのチャンネル数を指定することで、異なるチャンネルのすべてのサンプルをインターリーブします。
- [12]:サンプルタイプにSIMDRegisterラッパーを持つ単一のブロックコンテキストでインターリーブデータを使用してフィルターでオーディオを処理します。
- [13]:次に、各入力チャンネルについて、出力ブロックチャンネルポインタを対応するHeapBlockにコピーします。
- [14]:最後に、インターリーブAudioBlockからチャンネルポインタHeapBlockにコピーし、サンプル数とSIMDRegisterサイズとしてのチャンネル数を指定することで、異なるチャンネルのすべてのサンプルをデインターリーブします。
フィルターのreset()関数は両方のケースで同じままであり、最適化は完了です。
新しい係数ポインタを考慮してupdateParameters()関数を更新するだけです:
void updateParameters()
{
if (sampleRate != 0.0)
{
auto cutoff = static_cast<float> (cutoffParam.getCurrentValue());
auto qVal = static_cast<float> (qParam.getCurrentValue());
switch (typeParam.getCurrentSelectedID())
{
case 1:
*iirCoefficients = *dsp::IIR::Coefficients<float>::makeLowPass (sampleRate, cutoff, qVal);
break;
case 2:
*iirCoefficients = *dsp::IIR::Coefficients<float>::makeHighPass (sampleRate, cutoff, qVal);
break;
case 3:
*iirCoefficients = *dsp::IIR::Coefficients<float>::makeBandPass (sampleRate, cutoff, qVal);
break;
default:
break;
}
}
}
このコードの修正版のソースコードは、デモプロジェクトのSIMDRegisterTutorial_02.hファイルにあります。
まとめ
このチュートリアルでは、SIMDRegisterクラスを使用してDSPコードを最適化する方法を学びました。特に以下のことを行いました:
- SIMD命令の利点を学びました。
- IIRフィルターを通じてサウンドファイルを処理しました。
- SIMDRegisterクラスを使用してIIRフィルターを最適化しました。